The documentation you are viewing is for Dapr v1.7 which is an older version of Dapr. For up-to-date documentation, see the latest version.
操作方法:在 Kubernetes 中搭建 Fluentd、Elastic search 和 Kibana
先决条件
安装 Elasticsearch 和 Kibana
-
为监测工具创建命名空间并添加 Helm Repo 用于Elastic Search
kubectl create namespace dapr-monitoring -
添加 Elastic helm repo
helm repo add elastic https://helm.elastic.co helm repo update -
使用 Helm 安装 Elastic Search
默认情况下,Chart 必须在不同的节点上创建3个副本。 如果您的集群少于3个节点,请指定一个较低的副本数量。 例如,将它设置为 1:
helm install elasticsearch elastic/elasticsearch -n dapr-monitoring --set replicas=1
否则:
helm install elasticsearch elastic/elasticsearch -n dapr-monitoring
如果您正在使用 minikube 或者想要禁用持久化卷来开发,您可以使用以下命令禁用它:
helm install elasticsearch elastic/elasticsearch -n dapr-monitoring --set persistence.enabled=false,replicas=1
-
安装 Kibana
helm install kibana elastic/kibana -n dapr-monitoring -
校验
确保 Elastic Search 和 Kibana 正在您的Kubernetes 集群中运行。
kubectl get pods -n dapr-monitoring NAME READY STATUS RESTARTS AGE elasticsearch-master-0 1/1 Running 0 6m58s kibana-kibana-95bc54b89-zqdrk 1/1 Running 0 4m21s
安装 Fluentd
- 安装 config map 和 Fluentd 作为守护程序
下载这些配置文件:
注意:如果你已经在你的集群中运行 Fluentd,请启用 nested json 解析器从 Dapr 解析JSON 格式的日志。
将配置应用到您的集群:
kubectl apply -f ./fluentd-config-map.yaml
kubectl apply -f ./fluentd-dapr-with-rbac.yaml
- 确保 Fluentd 作为守护程序运行;实例的数量应与集群节点的数量相同。 在下面的例子中,我们只有一个节点。
kubectl get pods -n kube-system -w
NAME READY STATUS RESTARTS AGE
coredns-6955765f44-cxjxk 1/1 Running 0 4m41s
coredns-6955765f44-jlskv 1/1 Running 0 4m41s
etcd-m01 1/1 Running 0 4m48s
fluentd-sdrld 1/1 Running 0 14s
使用 JSON 格式化日志安装 Dapr
-
使用 JSON 格式化日志启用 Dapr
helm repo add dapr https://dapr.github.io/helm-charts/ helm repo update helm install dapr dapr/dapr --namespace dapr-system --set global.logAsJson=true -
在 Dapr sidecar 中启用 JSON 格式化日志
添加 dapr.io/log-as-json: "true" annotation 到你的部署yaml.
You can run Kafka locally using this Docker image. To run without Docker, see the getting started guide here.
apiVersion: apps/v1
kind: Deployment
metadata:
name: pythonapp
namespace: default
labels:
app: python
spec:
replicas: 1
selector:
matchLabels:
app: python
template:
metadata:
labels:
app: python
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "pythonapp"
dapr.io/log-as-json: "true"
...
搜索日志
注意: Elastic Search 需要一段时间才能索引 Fluentd 发送的日志。
- Port-forward 到 svc/kibana-kibana
$ kubectl port-forward svc/kibana-kibana 5601 -n dapr-monitoring
Forwarding from 127.0.0.1:5601 -> 5601
Forwarding from [::1]:5601 -> 5601
Handling connection for 5601
Handling connection for 5601
-
浏览
http://localhost:5601 -
点击Management -> Index Management
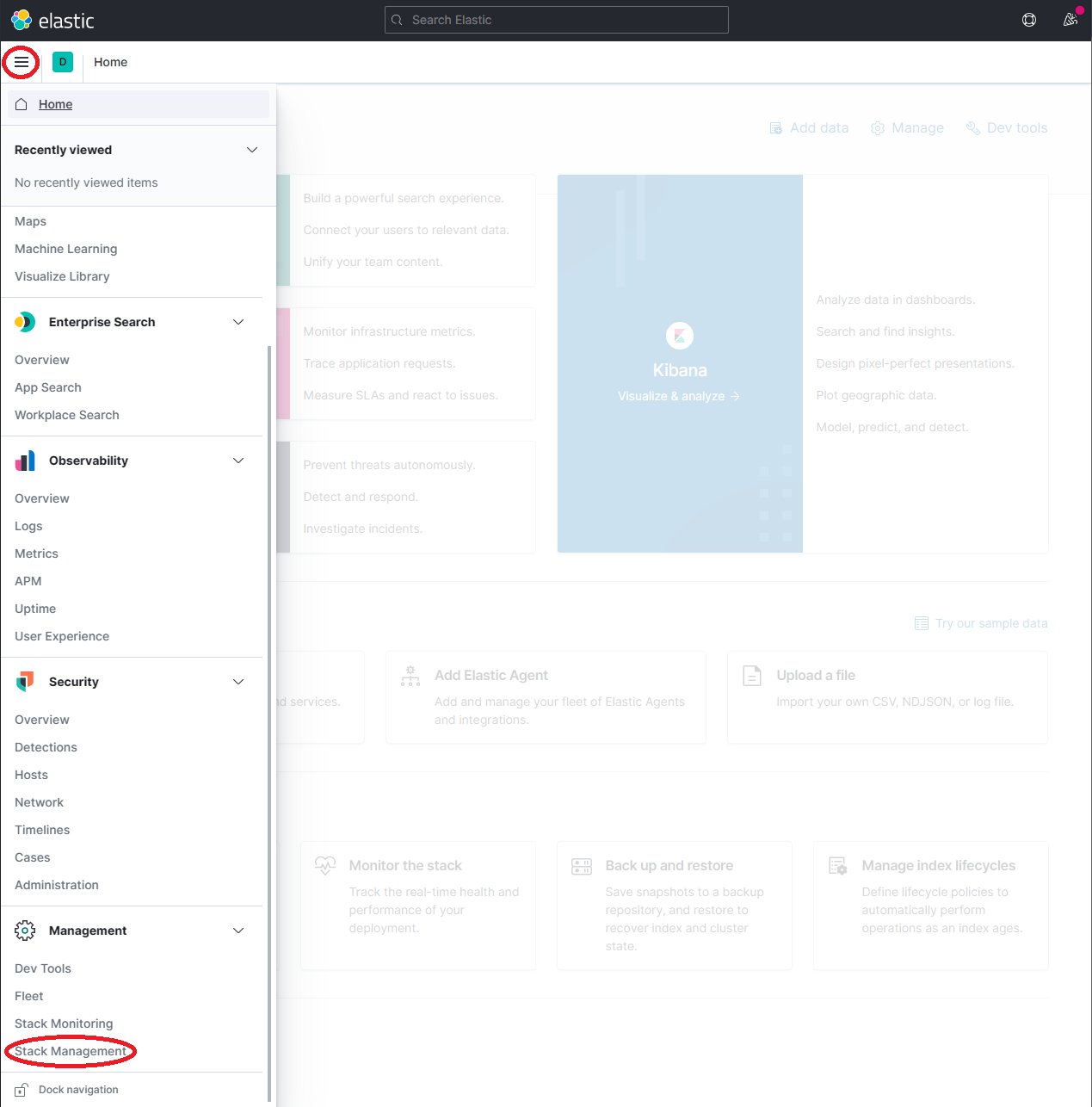
- 请稍候,直到Dapr-* 被索引。
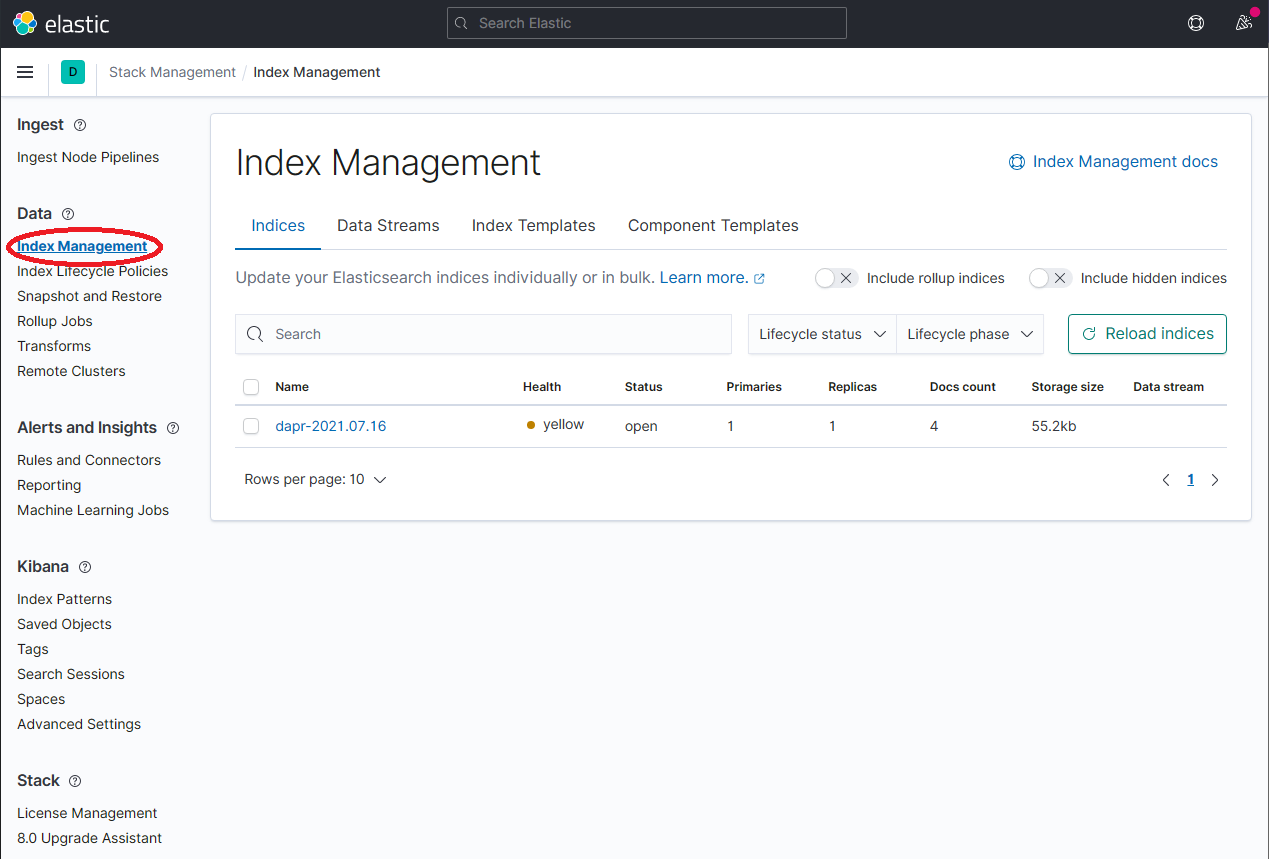
- 一旦dapr-* 被索引了,请点击 Kibana-> Index Patterns 并创建索引模式
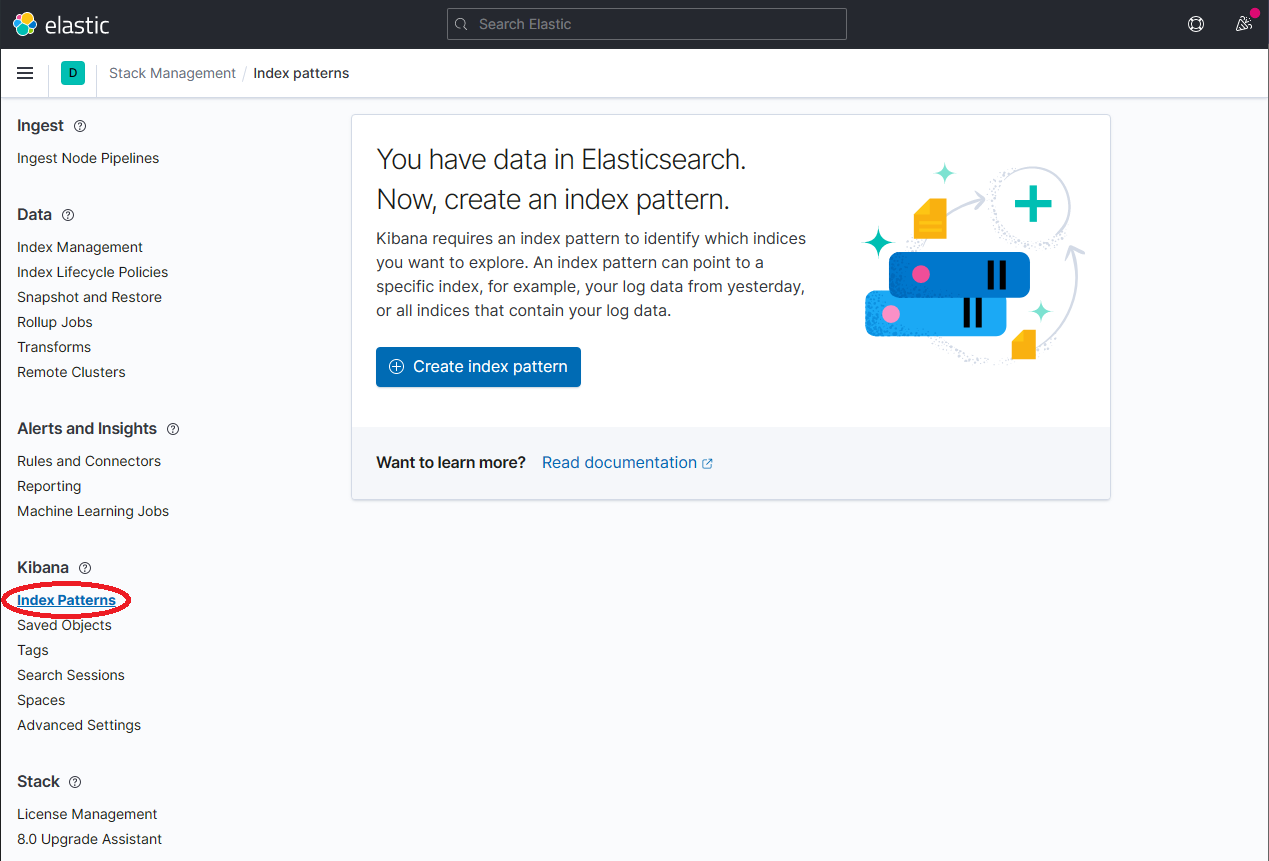
- 在index pattern中输入
dapr*定义索引模式
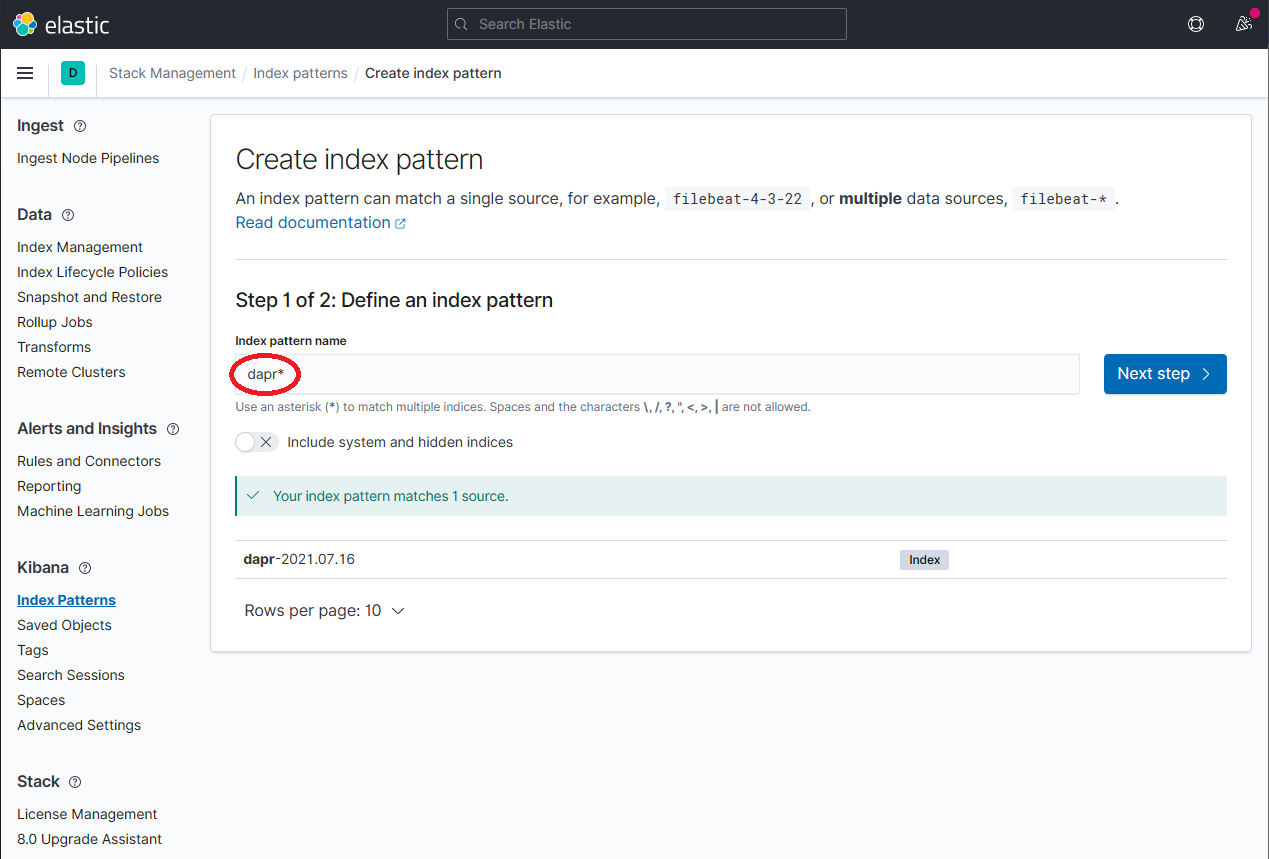
- 选择time stamp填入:
@timestamp
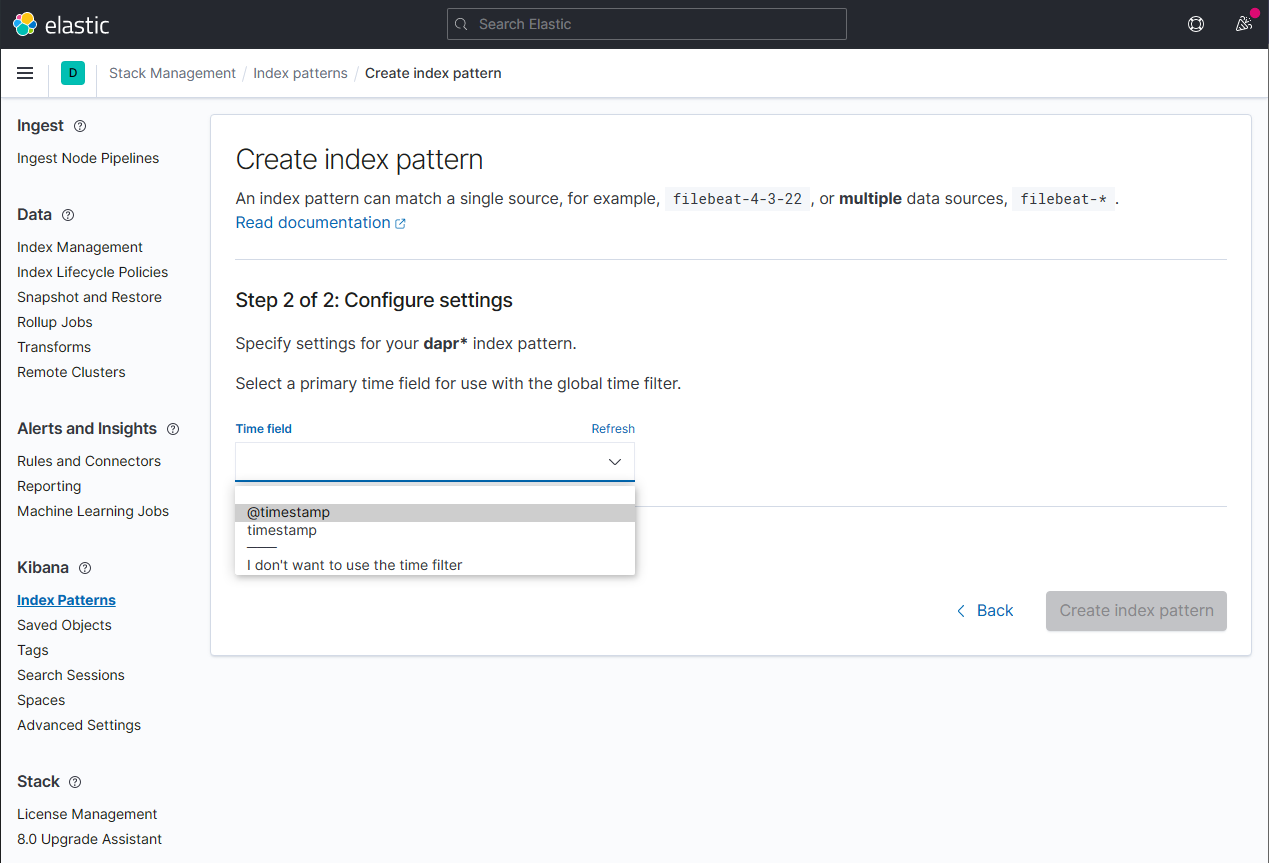
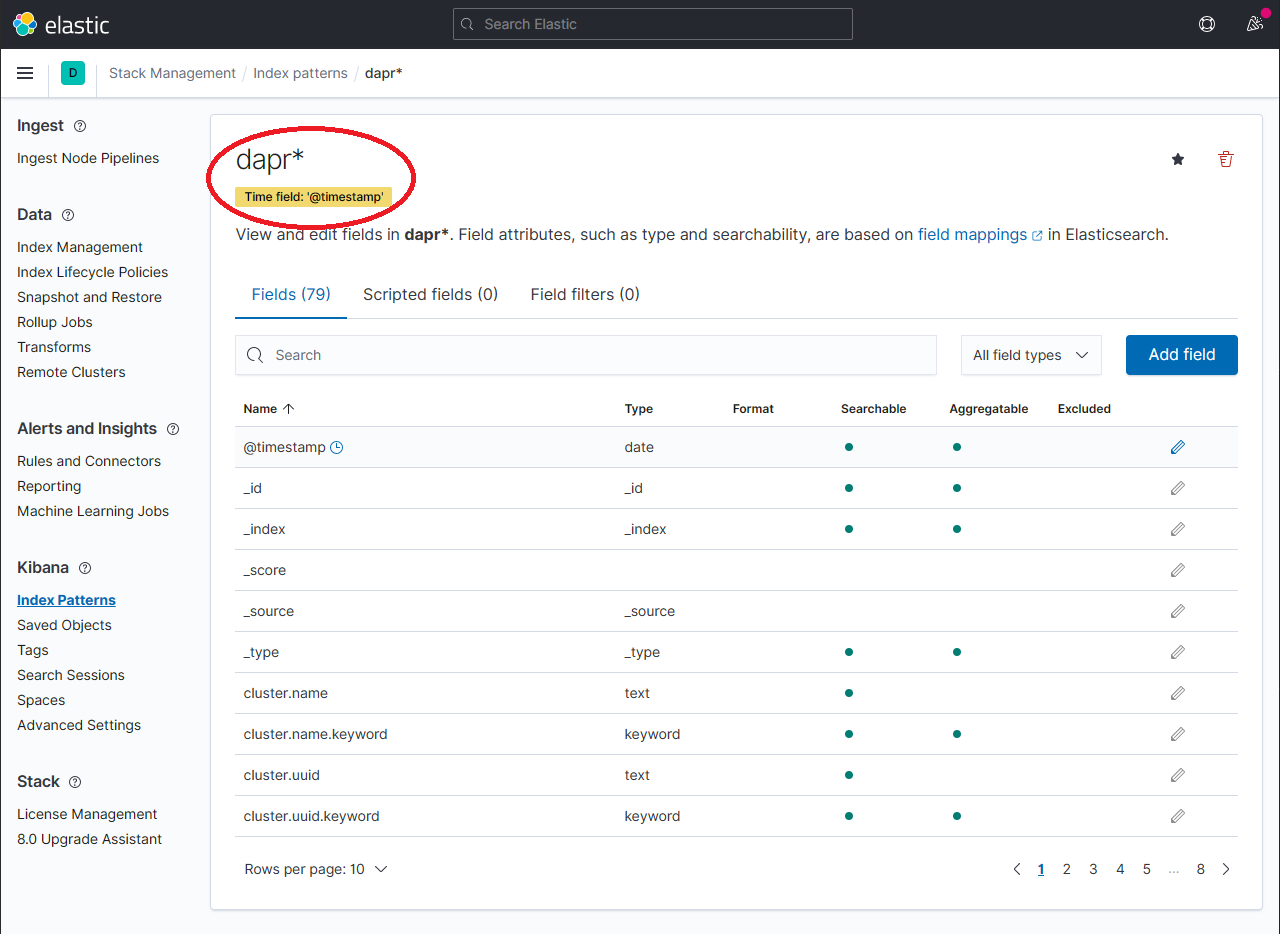
- 确认
scope,type,app_id,level, 等正在索引。
注意:如果您找不到索引字段,请稍候。 它取决于正在进行弹性搜索的数据量和资源大小。
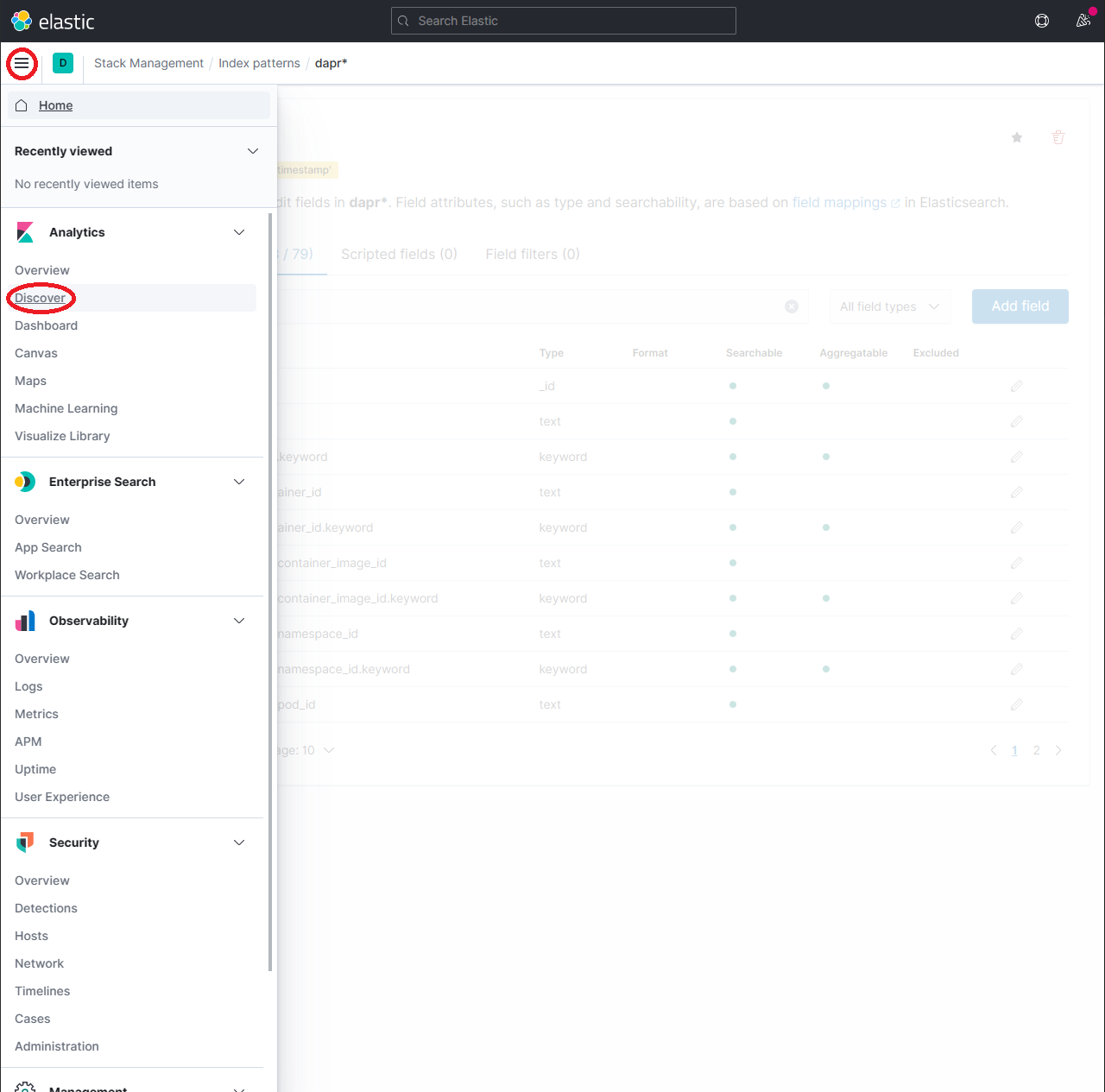
- 点击
discover图标并搜索scope:*
注:根据数据量和资源进行日志检索需要一些时间。
参考资料
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.